

Launch: Kafka Write Connector on #LetsData

Today, we are announcing the public availability of Kafka Write Connector on #LetsData. Customers can now create #LetsData datasets to automatically write documents to Kafka.
Challenges and Complexities
Developing the #LetsData Kafka write connector has been a challenging undertaking. Kafka is a mature product and has a rich ecosystem. Some challenges:
AWS implementations come in a couple of flavors - a Serverless option and a Provisioned option.
Different Kafka versions support additional features such as tiered storage.
Unlike its competitors such as Kinesis, AWS Kafka implementations require separate VPC and networking setup
Complexities around VPC connectivity, compounded by cross account access
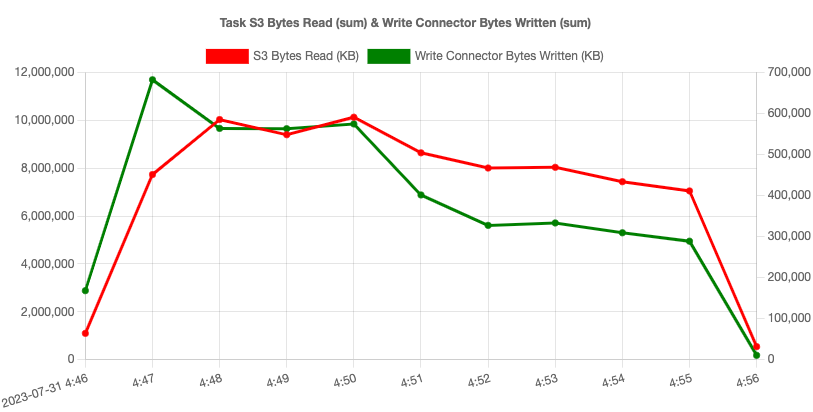
10 concurrent tasks, Kafka Provisioned Cluster, 6 t3 small nodes. S3 Read throughput max ~10 GB per min, Kafka Write throughput max ~ 700 MB per min We've resolved a bunch of these ambiguities in our implementation and automated the Kafka cluster setup and networking. With #LetsData Kafka Write Connector, you can create a working Kafka Cluster and a secure VPC within a few minutes. The connector comes with #LetsData trademark write performance, simplicity and operations.
You can read about the Kafka write connector in our docs at www.letsdata.io/docs#writeconnectors
VPC Networking
To manage the Kafka Write Connector Vpc and its connectivity, we’ve built an extensive networking subsystem and we are launching our Vpc & Vpc connectivity APIs today in our CLI. At a high level, we've implemented:
IP Address Management for the multi-tenant system with disparate IP Address allocations and reclamations for each dataset. We've used Vpc's IPAM (IP Address Manager) feature that works really well.
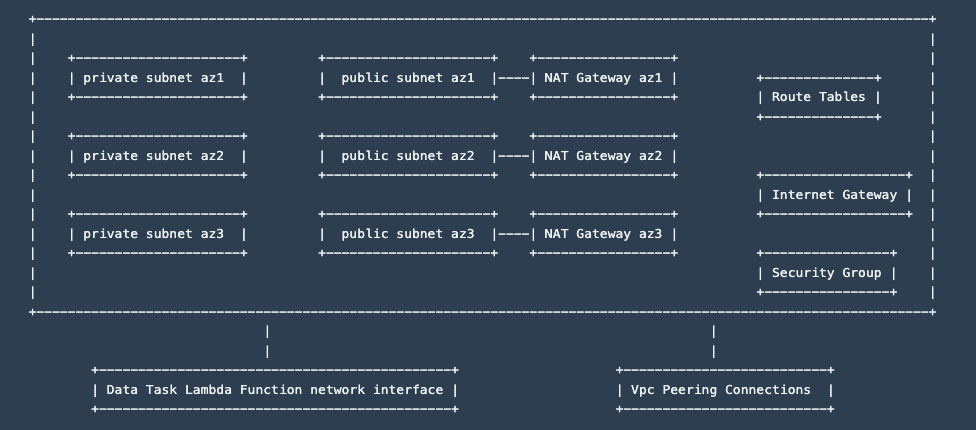
Setup a secure, isolated Vpc for each Kafka Write Connector, setup for outbound connectivity only. Here is the architecture at a glance:

Kafka Cluster VPC Architecture Connectivity to the resources in the Vpc via Vpc Peering - we've added self service APIs to establish connectivity.
# run this command with customerAccountForAccess's aws credentials $ > aws ec2 create-vpc-peering-connection --vpc-id 'clientVpcId' --peer-vpc-id 'letsdataVpcId' --peer-owner-id 'letsdataVpcOwnerId' --peer-region 'letsdataVpcRegion'# accept the vpc peering connection on behalf of #Let's Data by using the following #Let's Data CLI command $ > letsdata vpcs vpcPeeringConnections accept --datasetName 'datasetName' --vpcPeeringConnectionId 'vpcPeeringConnectionId' --requesterVpcId 'clientVpcId' --accepterVpcId 'letsdataVpcId' --prettyPrint# list the vpc peering connections for a #LetsData vpc $ > letsdata vpcs vpcPeeringConnection list --datasetName 'datasetName' --vpcId 'letsdataVpcId' [--userId 'userId']# delete a vpc peering connection for a #LetsData vpc $ > letsdata vpcs vpcPeeringConnections delete --datasetName 'datasetName' --letsdataVpcId 'letsdataVpcId' --customerVpcId 'customerVpcId' --vpcPeeringConnectionId 'vpcPeeringConnectionId' [--userId 'userId']You can read the technical details around our Vpc subsystem at www.letsdata.io/docs#vpcs
Support Matrix
We support Kafka Serverless and Kafka Provisioned in the #LetsData account (resourceLocation: LetsData). We also support Kafka Provisioned as BYOC (Bring Your Own Cluster) when the Kafka cluster is located in an external AWS account. (ResourceLocation: Customer).

Support Matrix for Kafka Provisioned Write Connector 
Support Matrix for Kafka Serverless Write Connector That is quite a feature and test matrix for a write connector destination! What we seemed to have built is either at the bleeding edge for these technologies (or a small chance that we are doing it wrong and no one does it this way!) Why? Well, we ran into a couple of issues that cut short this matrix:
The AWS MSK IAM Auth externalId issue: AWS MSK IAM Auth is a seamless authentication library that solves the authentication in such a simple way (kudos AWS IAM folks!). However, it did seem like we had to build a custom version for our use case. GitHub Issue
Lambda Functions connecting to Vpc in a different account - Lambda functions work with Virtual Private Clouds by establishing elastic network interfaces to the Vpc subnets and accessing the resources in the subnets. However, this seems to be limited to Vpc's in the same account (So lambda cannot connect to Kafka cluster in customer account). Some creative networking (with Vpc Peering) is probably required, but as of now, it isn't supported out of the box. This is why the Kafka Cluster in the Customer AWS Account has only 1 supported case - when the cluster is publicly available (and accessible to Lambda).
Example: Create a Dataset
The examples that have the step by step instructions have been updated for a Kafka Serverless write connector. (www.letsdata.io/docs#examples)
Here is an example dataset configuration and commands to create the dataset.
{ "datasetName": "ExtractTargetUriDemoTest", "accessGrantRoleArn": "arn:aws:iam::308240606591:role/Extractor", "customerAccountForAccess": "308240606591", "readConnector": { "connectorDestination": "S3", "bucketName": "commoncrawl", "bucketResourceLocation": "Customer", "readerType": "Single File Reader", "singleFileParserImplementationClassName": "com.letsdata.example.TargetUriExtractor" "artifactImplementationLanguage": "Java", "artifactFileS3Link": "s3://targeturiextractorjar-demotest/target-uri-extractor-1.0-SNAPSHOT-jar-with-dependencies.jar", "artifactFileS3LinkResourceLocation": "Customer" }, "writeConnector": { "connectorDestination": "KAFKA", "resourceLocation": "LetsData", "kafkaClusterType": "Serverless", "kafkaTopicName": "commoncrawl", "kafkaTopicPartitions": 5, "kafkaTopicReplicationFactor": 3, "kafkaClusterSize": "small" }, "errorConnector": { "connectorDestination": "S3", "resourceLocation": "letsdata" }, "computeEngine": { "computeEngineType": "Lambda", "concurrency": 15, "memoryLimitInMegabytes": 10240, "timeoutInSeconds": 900, "logLevel": "DEBUG" }, "manifestFile": { "manifestType": "S3ReaderTextManifestFile", "readerType": "SINGLEFILEREADER", "fileContents": "crawl-data/CC-MAIN-2022-49/segments/1669446706285.92/warc/CC-MAIN-20221126080725-20221126110725-00000.warc.gz\r\ncrawl-data/CC-MAIN-2022-49/segments/1669446706285.92/warc/CC-MAIN-20221126080725-20221126110725-00001.warc.gz\r\ncrawl-data/CC-MAIN-2022-49/segments/1669446706285.92/warc/CC-MAIN-20221126080725-20221126110725-00002.warc.gz\r\ncrawl-data/CC-MAIN-2022-49/segments/1669446706285.92/warc/CC-MAIN-20221126080725-20221126110725-00003.warc.gz\r\ncrawl-data/CC-MAIN-2022-49/segments/1669446706285.92/warc/CC-MAIN-20221126080725-20221126110725-00004.warc.gz\r\ncrawl-data/CC-MAIN-2022-49/segments/1669446706285.92/warc/CC-MAIN-20221126080725-20221126110725-00005.warc.gz\r\ncrawl-data/CC-MAIN-2022-49/segments/1669446706285.92/warc/CC-MAIN-20221126080725-20221126110725-00006.warc.gz\r\ncrawl-data/CC-MAIN-2022-49/segments/1669446706285.92/warc/CC-MAIN-20221126080725-20221126110725-00007.warc.gz\r\ncrawl-data/CC-MAIN-2022-49/segments/1669446706285.92/warc/CC-MAIN-20221126080725-20221126110725-00008.warc.gz\r\ncrawl-data/CC-MAIN-2022-49/segments/1669446706285.92/warc/CC-MAIN-20221126080725-20221126110725-00009.warc.gz" } }


# create the dataset on #Let's Data using the CLI.
$ > ./letsdata datasets create --configFile datasetConfiguration.json --prettyPrint
# view the dataset on #Let's Data using the CLI. Once the dataset is created, it takes ~3 mins to initialize the resources (dataset is in INITIALIZING state, no tasks have been created yet).
$ > ./letsdata datasets view --datasetName ExtractTargetUriDemoTest --prettyPrint
# list the dataset tasks on #Let's Data using the CLI
$ > ./letsdata tasks list --datasetName ExtractTargetUriDemoTest --prettyPrintExample: SDK Sample
We’ve also updated our SDK samples on how to read data from #LetsData Kafka clusters. (https://github.com/lets-data/letsdata-writeconnector-reader and www.letsdata.io/docs#customeraccountforaccess)
Here is the sample CLI driver application that can be used to read from the Kafka cluster. This assumes connectivity to the VPC has been established. (Instructions on how to establish connectivity can be found at: www.letsdata.io/docs#vpcs)
# cd into the bin directory
$ > cd src/bin
# awsAccessKeyId and awsSecretKey are the security credentials of an IAM User in the customer AWS account. This is the customer AWS account that was granted access. In case this is a root account, you can create an IAM user. See the "IAM User With AdministratorAccess" section above.
# Connect a Kafka Consumer to the Kafka Cluster using aws-msk-iam-auth library
$ > kafka_reader --clusterArn 'clusterArn' --customerAccessRoleArn 'customerAccessRoleArn' --externalId 'externalId' --awsRegion 'awsRegion' --awsAccessKeyId 'awsAccessKeyId' --awsSecretKey 'awsSecretKey' --topicName 'topicName'
> Enter the kafka consumer method to invoke. ["listTopics", "listSubscriptions", "subscribeTopic", "pollTopic", "commitPolledRecords", "topicPartitionPositions","assignTopicPartitions", "listAssignments","quit"]
listTopics
{commoncrawl1}
> Enter the kafka consumer method to invoke. ["listTopics", "listSubscriptions", "subscribeTopic", "pollTopic", "commitPolledRecords", "topicPartitionPositions","assignTopicPartitions", "listAssignments","quit"]
assignTopicPartitions
> Enter the kafka consumer method to invoke. ["listTopics", "listSubscriptions", "subscribeTopic", "pollTopic", "commitPolledRecords", "topicPartitionPositions","assignTopicPartitions", "listAssignments","quit"]
topicPartitionPositions
{commoncrawl1={0=0, 1=0, 2=0, 3=0, 4=0}}
> Enter the kafka consumer method to invoke. ["listTopics", "listSubscriptions", "subscribeTopic", "pollTopic", "commitPolledRecords", "topicPartitionPositions","assignTopicPartitions", "listAssignments","quit"]
pollTopic
...
...
...
> Enter the kafka consumer method to invoke. ["listTopics", "listSubscriptions", "subscribeTopic", "pollTopic", "commitPolledRecords", "topicPartitionPositions","assignTopicPartitions", "listAssignments","quit"]
commitPolledRecords
> Enter the kafka consumer method to invoke. ["listTopics", "listSubscriptions", "subscribeTopic", "pollTopic", "commitPolledRecords", "topicPartitionPositions","assignTopicPartitions", "listAssignments","quit"]
topicPartitionPositions
{commoncrawl1={0=179, 1=424, 2=249, 3=185, 4=233}}
> Enter the kafka consumer method to invoke. ["listTopics", "listSubscriptions", "subscribeTopic", "pollTopic", "commitPolledRecords", "topicPartitionPositions","assignTopicPartitions", "listAssignments","quit"]
quitOur docs, CLI and web have all been updated to work with Kafka Write Connector.
Conclusion
With these new Vpc & Clustering subsystems, we’ll now be looking to add additional clustering data destinations to LetsData. We also have plans to expand the Read Connectors to Kinesis, DynamoDB and Kafka.
We hope you’d like working with the newer features and would love to hear any feedback on what works well / doesn’t work well.