

Launch: Kinesis Stream Read Connector is now available

Today, we are announcing the public availability of Kinesis Read Connector on #LetsData. Customers can now create #LetsData datasets to automatically read documents from Kinesis Streams.
Customers implement the KinesisRecordReader interface to transform Kinesis records to output documents. #LetsData handles reading from the stream, managing compute and writing to your selected write destination.
Implementation
While we discuss the implementation, there are a few interesting discussion points that should be explored:
Queues vs. Streams
When I first started looking at streams I grappled with the obvious question - What is the difference between a queue and a stream? I had worked with SQS and was now looking into Kinesis, and on the surface both seemed to have the similar sendMessage and getMessage semantics. For those who don’t work with queues / streams in their everyday jobs or are at the periphery of these technologies, do research this simple question. The internalizations of the differences that have stayed with me are:
Queue messages are ephemeral - you consume them and they are gone (messages are deleted / dequeued). Streams tend to be more like a database records - you consume them and they are still there, available for different consumers to read as well (when message are read, your read pointer is advanced to next record).
Queues are like glue that connect two systems and are created specifically for that system’s use-case example, sendMessage(“a task has been created, kindly assign to a worker”). Streams are more akin to a broadcast - where the stream can be used by many different systems, example sendMessage(“a task was created”). The many stream readers could do different actions for the same message. A monitor process will create alarms on the task, a scheduler will create a worker to assign task and a reporting process will generate a report of the number of tasks created per hour.
Ordering guarantees are much stronger in streams vs queues. Queues are mostly unordered or at best offer FIFO ordering semantics. Streams on the other hand allow for sequencing records, which allows for distributed events reasoning such as happens-before relationships and ordering of events.
The common stream implementations have stronger facilities for key-space control and sharding vs common queue implementations which do not have as flexible key-space / partitioning control.
This lends queues to be a great fit for message passing scenarios. Streams, on the other hand, are best for real time data processing and analysis.
Architecture
The architecture of a Kinesis Stream Reader Task in LetsData is similar to an SQS task, with the implementations being quite different. Here is a high level task architecture:

Following are some interesting implementation details:
Read Acknowledgements
SQS read connector is complicated in that it:
reads the message from the queue which essentially is a lease for a certain duration
maintains the lease and renews it if needed
when processing is complete, deletes the message (read acknowledgement)
there are no offsets, messages have been deleted, so checkpointing is mostly for progress reporting.
The Kinesis read connector read does not need any lease management and there isn’t any read acknowledgement needed. You read the record, process and then checkpoint the offset (sequenceNumber). This simplifies the reader and also increases the read throughput (one less call to make).
Batched Reads, Network Calls and Concurrency
In Kinesis Stream Reader, we use the batched read API to read 30 records and then for each record we call the user’s interface implementation to get the transformed doc. While testing, we ran into a couple of very interesting issues:
The calling user’s interface implementation was essentially serial, which meant that we loop over the 30 records and call them one by one. This worked great when the user’s interface implementations were in-proc (java). With python/javascript, we added network calls which meant that user’s interface implementations latency was 30*latency of single network call. We fixed this to be done in parallel and saw significant performance increase (100 ms → 20 ms).
When we added the above parallelism, we started seeing Out of Memory - Unable to create a native thread errors. Lots of debugging, stack dumps and code analysis later, it turned out that we were using the
Executors.newFixedThreadPool(1000)method to create our threadpool. This had worked great but with the recent large increase in threads, it looked like the thread reclamation was somehow not happening fast enough in certain scenarios. We switched the threadpool to aThreadPoolExecutor- specifying custom values for core pool size (100), max pool size (1000), a relatively aggressive thread reclamation timeout (500 ms), a custom thread factory that assigned stacktrace names to the thread and added threadpool statistic logs. We’ve not seen any issues since this change, threads are constantly around 100 (the core pool size) and thread reclamation is working quite well.
Offsets
Our S3 readers were file based, so our offsets were integers i.e. number of bytes into the file. With SQS, we didn’t need offsets. With Kinesis, we started seeing offsets(sequenceNumbers) which were very large integers, for example, 49647350647089693080323675671827096928861743259506966562. The engineer in me is curious as to how such numbers might be generated and if they are increasing numbers or not. However, that is not important. What is important is that integers were probably not a great idea for offsets especially when we are dealing with a myriad of read resources. So the offsets needed to be string.
We reworked our stack to store offsets as strings - the each destination’s readers can make sense of the offset according to their own logic, but to the overall system, these are opaque strings. This did require an update to our data interfaces as well (breaking change).
These are some interesting implementation tidbits that I thought readers might like and it might help them avoid similar issues / design better systems. Now let’s look at how we can actually develop on LetsData using this new read connector.
Getting Started
Getting started with the Kinesis Stream read connector requires implementing the interface (Code), defining config (Config), granting #LetsData access (Access) and then running the dataset using CLI (CLI).
Code
The KinesisRecordReader is a simple interface that has a single parseMessage method that needs to be implemented.
You can look at the interface definition on GitHub (Java, Python, Javascript) and example implementations that simply echo the incoming record on GitHub as well (Java, Python, Javascript). These are also available on our read connector docs.
Here is the example code in different supported languages that shows simplicity and ease of integration.

Config
Define the read connector config which is simply the interface implementation details and the Kinesis Stream ARN. Read Connector Config on LetsData Docs has details and examples.
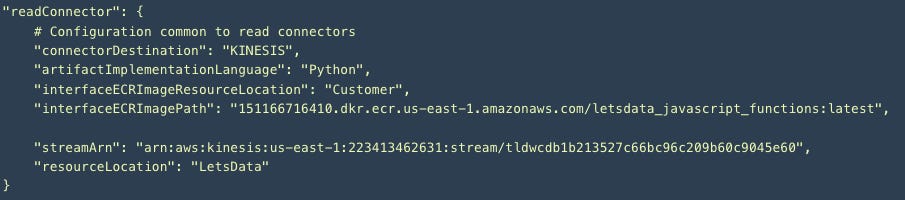
Access
Trust #LetsData to access the Kinesis stream AWS account by creating an IAM Role that trusts the LetsData account. Details at Access Grants Docs

Create a policy to allow access to the Kinesis stream. Access Grants Docs

Create the policy and attach to role. Access Grant Docs


This should allow LetsData to access the Kinesis stream in the Customer’s AWS account. You may also want to look at the Examples to get a step by step of the access grant process, be sure to replace the policy with the Kinesis stream policy.
CLI
Okay, now let’s create the dataset using the LetsData CLI. Download and Setup Instructions
Create the dataset configuration incorporating the read connector configuration from the Config section above. Examples have a step by step rundown.
Create the dataset, monitor execution via CLI or via the LetsData Website

Conclusion
Kinesis streams is a very powerful technology and can be used in a variety of different use-cases. #LetsData simplifies reading and writing to Kinesis - user has to write their business case logic only while #LetsData manages the read, write and processing infrastructure.
Thoughts? Let us know. Happy to chat!