

#LetsData is now available in 6 AWS regions

Today, we are announcing the launch of multi-region support for #LetsData.
#LetsData is now available in the following AWS regions:
us-east-1 (N. Virginia)
us-west-2 (Oregon)
us-east-2 (Ohio)
eu-west-1 (Ireland)
ap-south-1 (Mumbai)
ap-northeast-1 (Tokyo)
You can read about the feature details in our our docs [1].
Background: Data Locality
Before we get into the details of the #LetsData multi-region feature, let’s look at why multi-region support is important in modern day data processing.
Data and Compute Locality
Google’s Map Reduce [2] and Apache’s Hadoop / HDFS [3] are seminal technologies for large scale distributed data processing. One of the key design tenets from these systems is about the data locality.
From the HDFS architecture:
A computation requested by an application is much more efficient if it is executed near the data it operates on … The assumption is that it is often better to migrate the computation closer to where the data is located rather than moving the data to where the application is running.
From the Map Reduce paper:
The MapReduce master takes the location information of the input files into account and attempts to schedule a map task on a machine that contains a replica of the corresponding input data. Failing that, it attempts to schedule a map task near a replica of that task’s input data (e.g., on a worker machine that is on the same network switch as the machine containing the data). When running large MapReduce operations on a significant fraction of the workers in a cluster, most input data is read locally and consumes no network bandwidth.
These works are from ~ 2004/2005, when cloud computing either didn’t exist or was in infancy. Google Map Reduce paper cites commodity hardware, IDE disks and 100 Mbps - 1 Gbps ethernet.
AWS, EC2 and Network Bandwidth
With the likes of AWS and EC2 instances with 25 Gbps - 100 Gbps bandwidths available to services like S3 at reasonable costs, in my humble experience, the code optimizations for data locality to be on the same machine, rack or network switch might not be necessary. For example, here are the m5n instance types and their available network bandwidths and hourly costs.[4]

(The costs by themselves are affordable in my opinion. For example the m5n.25xlarge / m5n.metal costs are around $4,100 per month. These can also be decreased drastically if one were to use reserved instances or spot instances).
And we see very nice performance even in higher level services such as AWS Lambda (that might be built on top of this EC2 infrastructure) when reading / writing to AWS services such as S3 and Kinesis etc [5].
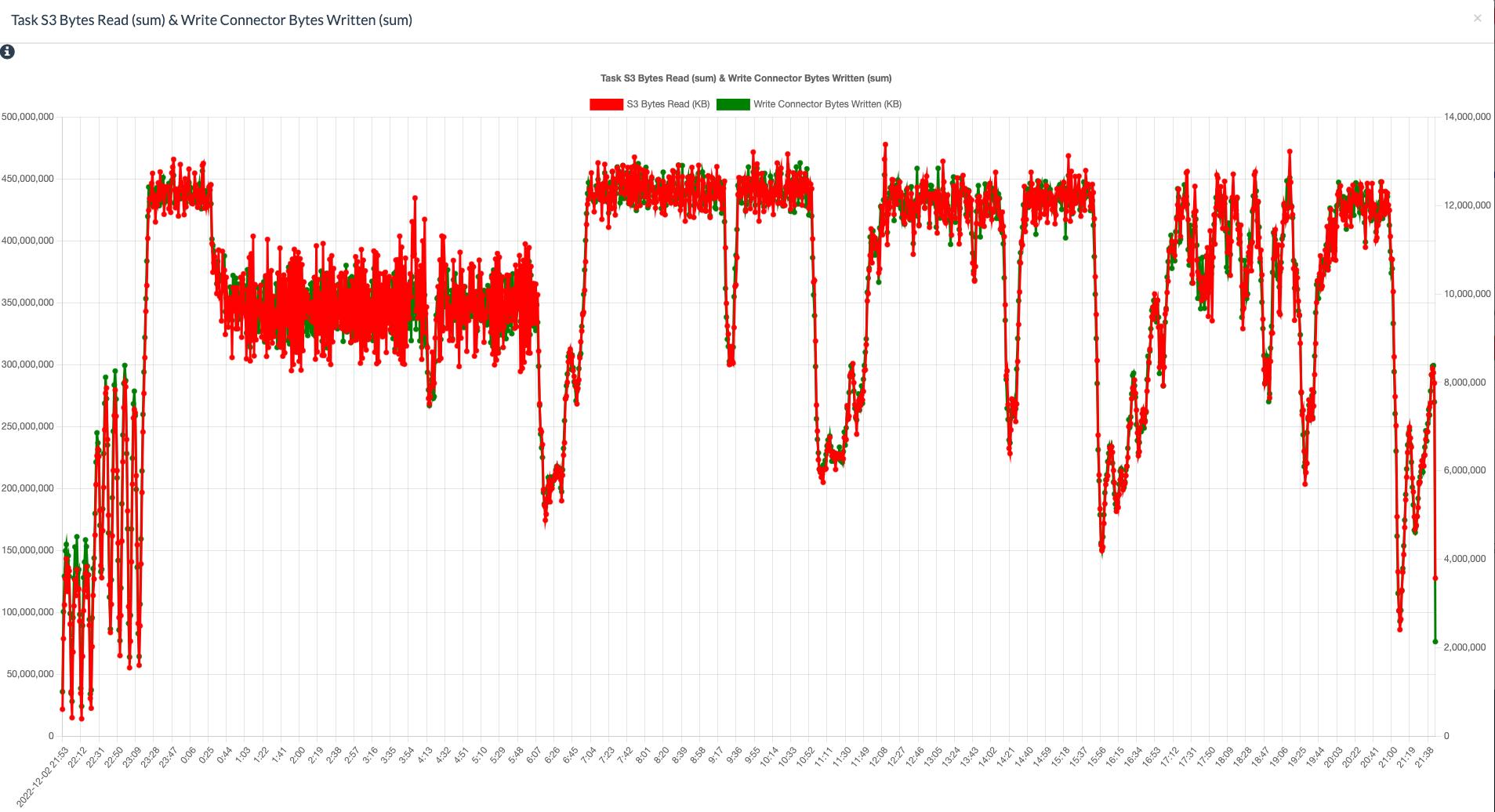
So, to re-iterate my humble observation from above, the code optimizations for data locality to be on the same machine, rack or network switch might not be necessary.
What about same AWS availability zone? Same AWS region (different availability zone)? Same geographical region (different AWS region)? Different geographical region? (For those who need a primer about these concepts, see this page about AWS Global Infrastructure [6] and about regions and availability zones[7] )
Lets look at some latencies [8]

So within the same region, we can expect a p99 latency < 10 milliseconds. The website doesn’t breakdown numbers for within an availability zone or across availability zones, but Michael Haken’s blog post [10] suggests that sub millisecond latency within same availability zone can be expected. Within the same datacenter latency and its comparison with disk [11]
Round trip within same datacenter 500,000 ns
Disk seek 10,000,000 ns
To reason about the latency and throughput, refer to Brad Hedlund’s post [9].
Reduce latency? How is that possible? Unless you can figure out how to overcome the speed of light there is nothing you can do to reduce the real latency between sites. One option is, again, placing a WAN accelerator at each end that locally acknowledges the TCP segments to the local server, thereby fooling the servers into seeing very low LAN like latency for the TCP data transfers.
So, the reality here is that you probably cannot be faster than the speed of light - instagram animation, speed of light does 7.5 orbits around earth in 1 second, so to travel across the world it would need 1000/7.5 => 133 milliseconds. Light needs 133.33 milliseconds to travel around the world.
With this reasoning, in my humble opinion, you’d get acceptable performance by being closer to your data, in-region vs. cross region and can probably get away with not being on the same machine, rack or network switch.
So, in case your data is in Europe, you’d now benefit from the #LetsData compute availability in eu-west-1 (Ireland) !
#LetsData Dataset Types
Okay, enough about the background, what can we do with #LetsData’s availability in multiple regions?
With multi-region support, Datasets on LetsData can now either be in a single region or cross-region.
Single Region Datasets: Single region datasets are completely located in a single region and all resources required for the dataset processing (read destination, write destination, error connector, artifacts and compute engine) are located in the same region
Cross-Region Datasets: Cross region datasets are where the dataset resources (read destination, write destination, error connector, artifacts and compute engine) are located in different regions.
Dataset configuration defines whether a dataset is single region or cross region. The dataset configuration supports specifying the region either at the dataset level (single region) or individually at each resource level (cross region). This gives flexibility to create configurations according to the dataset needs.
Here is an example schema for dataset configuration with regions.
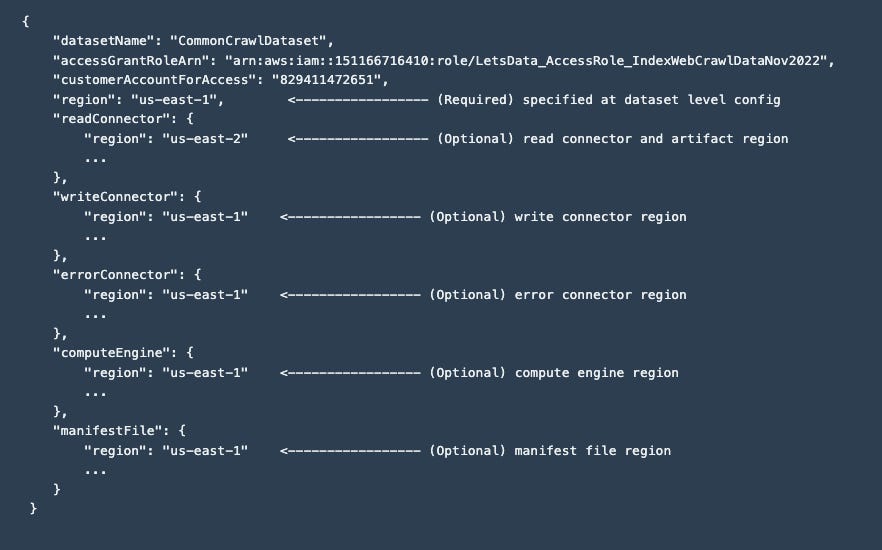
The Compute Engine region is probably the most important region for the dataset - this is the center of the dataset and where all the processing happens, essentially all distances (in region, cross region) have this region as its origin.
Interesting Dataset Configurations
Ideally, all processing should be done in-region for best performance and costs, but with multi-region support, one can now create a number of interesting different configurations to prioritize reads, writes or errors. For example:
Prioritizing for In-Region Reads: By selecting the compute region to be the same as the read region, one can prioritize reads to be in-region reads whereas writes can be in a different region. This is essentially pinning the compute region with the read region. This configuration is useful when the data read is much much greater than writes (and reads and writes need to be in different regions.)
Prioritizing for In-Region Writes: By selecting the compute region to be the same as the write region, one can prioritize writes over reads - essentially pinning the compute region with the write region. This configuration is useful when the writes are significant in comparison to the reads.
Degenerative case: The academic degenerative case for dataset component regions is where every component is in a separate region. We've tested this scenario, and it works.
#LetsData Regions Implementation Design
How have we implemented #LetsData regions? We’ve partitioned a dataset into two obvious components: a control component and a data component.
Control Component: The control component is the dataset’s creation, initialization and management. These are low volume, one time / few time operations where we setup resources for data processing. Since these are one time / low volume, we run these in us-east-1 region. Again, since these are infrequent, even a 250 ms cross region call from ap-south-1 should be okay and scalable as of now.
Data Component: The data component is the Data Task Lambda Function and the Sagemaker endpoints (if any) and they are created in the Compute Region. All the data processing happens in the Compute Region, data access, checkpointing, task processing etc. The only call across region is at the completion of tasks when we let the control process know that the tasks have completed.
Here is the dataset and task lifecycle and the split between control and data components:

Learnings
Here are some learned best practices from experience:
perfecting a task in a single region and then replicate it across geographies
question every task being replicated as to whether it is needed in replicating region or not? Managing 1 region vs 6 regions is a very different effort - you’d have copies of credentials, storage, compute, logs, metrics and other such infrastructure. Try and see what the system performance would be if something is not regionalized.
deep dive into components when replicating across geographies, its very easy to add regions with a sub optimal architecture - beware of the hidden cross region calls and that non regionalized component that you didn’t know was also part of the architecture.
run tests in different regions, analyze usage and look for any regional / cross region usage / data transfer. You might find a bug or two.
One thing we did was that instead of replicating databases across regions for low latency, we clearly separated the control databases and data databases. Control databases are only in the us-east-1 region and are accessed by control components only. Data databases are in the data regions and are accessed by data components only. This helped us get away without having to have global tables and cross region replication. While these features are great, as of now, not having to deal with such complexity is better architecture IMHO.
A few things we would like to do but have deferred:
API availability in each region with regional api and code deployments - add management overhead as of now
Separate AWS Accounts for each region - currently we are using a single AWS Account for all regions - again, having separate accounts is probably better scaling decision, but its a lot more work to manage
Additional Reads?
Our Distributed Computing field is quite large and while I have read some papers and tried to form an opinion, I am sure many important papers since the ones I mentioned have advanced this field. If there are any must reads in this area, do share - I’d love to learn what people have done in this space.
Thoughts / feedback, let me know.
References:
[1] Region documentation on #LetsData - https://www.letsdata.io/docs#regions
[2] Google Map Reduce - https://storage.googleapis.com/pub-tools-public-publication-data/pdf/16cb30b4b92fd4989b8619a61752a2387c6dd474.pdf
[3] Apache Hadoop - https://hadoop.apache.org/docs/r1.2.1/hdfs_design.pdf
[4] EC2 Instance Type Pricing - https://aws.amazon.com/ec2/pricing/on-demand/
[5] #LetsData Case Study: Big Data: Building a Document Index From Web Crawl Archives - https://www.letsdata.io/#casestudies - PDF
[6] AWS Regions and Availability Zones - https://docs.aws.amazon.com/whitepapers/latest/get-started-documentdb/aws-regions-and-availability-zones.html
[7] Regions and Zones - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-regions-availability-zones.html#concepts-regions-availability-zones
[8] AWS Latency Monitoring - https://www.cloudping.co/grid/p_99/timeframe/1M
[9] How to Calculate TCP throughput for long distance WAN links - https://bradhedlund.com/2008/12/19/how-to-calculate-tcp-throughput-for-long-distance-links/
[10] Improving Performance and Reducing Cost Using Availability Zone Affinity - https://aws.amazon.com/blogs/architecture/improving-performance-and-reducing-cost-using-availability-zone-affinity/
[11] Are networks now faster than disks - https://serverfault.com/questions/238417/are-networks-now-faster-than-disks