

Metrics, Data Visualizations & Dashboards

Metrics, Dashboards and Instrumentation results are essential for a number of reasons - the reason I like them is the sense of accomplishment and achievement you feel as an engineer when you see that your code has processed terabytes of data and is scaling to handle thousands of requests per second (I know - such vanity!). Short of customer commendation, such positive reinforcement can be a proxy of success and a powerful motivator. But I digress.
Metric Definition
Metrics, Dashboards and Instrumentation results give a view into the running of the service, whats going as expected, what is an anomaly and how the overall system is performing. While this would be a great explanation of a service’s operational dashboard, the science around dashboards goes much deeper. One classification that is simple and that I liked were classifying a metric / dashboard as either exploratory or explanatory. Here is a visual from Brent’s Linked In post that talks about this [1]:
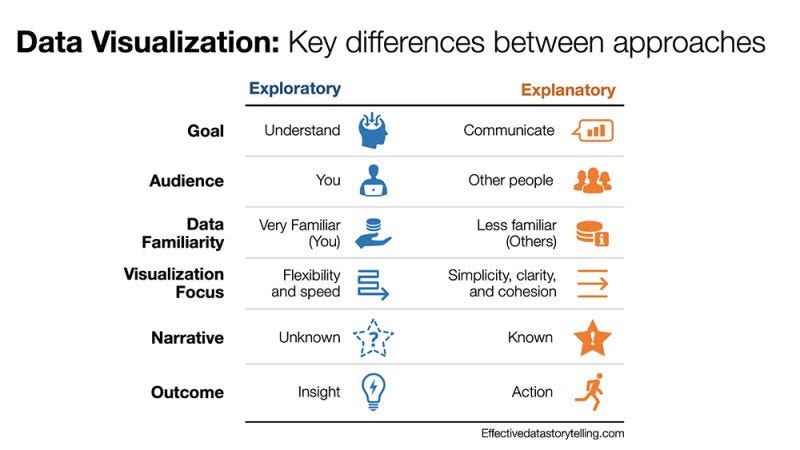
While we weren’t thinking this deeply when we implemented our metrics but in hindsight, it makes sense to apply this theory to our metrics. We essentially wanted to answer these primary questions:
What do we intend to communicate with the metric / visualization? (Goal in Brent’s post)
What will the viewer view this visualization for (or the action that they would take)? (Outcome in Brent’s post)
Some of the other dimensions he mentions were implicitly assumed during our work:
audience is a LetsData user (audience)
the LetsData user is familiar with the task and data domain (data familiarity)
the LetsData user would want to know about the system’s performance (visualization focus)
the user knows the narrative as it is specific to each metric - throughput from a read destination, scaling of a write destination etc (narrative)
What Should I Instrument?
So what do I instrument? Well, it depends on what are you intending to learn. For example, for my earlier startup, we measured the customer acquisition funnel and how it was changing over time with the experiments that we were running [2]. These were essentially business KPIs that told us how healthy the business was.
With LetsData, we are a developer focused offering and a lot of focus is on making sure that we provide the developers with visibility into the different parts of the system that they have delegated to LetsData. This is essentially:
a service’s operational dashboard
operators can use these to tune or correct the service
operators can monitor the different components of the service and reason about the overall progress
A large part of what to instrument is intuitive and comes with experience developing, operating and monitoring services. When you are developing code, it becomes second nature to add metrics for long running cpu work, network calls and other such tasks. Also, not all these instrumentation need to be in the final service dashboards.
What we decide to display on the Service Level Dashboard needs to answer some need that user may have. One way to achieve this is to draw your system’s architecture diagram and reason about what components users would want to know more about. This approach seems to be consistent with different system analysis tasks - Threat Model Diagrams in Security, Data Flow Diagrams in Software Design etc. Generally, when unsure about some system aspects, drawing a diagram and breaking it into components helps as a divide and conquer approach.
Let’s look at the #LetsData Task architecture diagram and see how we’ve reasoned about a handful of top level metrics for the dashboard.


The first step in task lifecycle is the task start or task processing. As a #LetsData Task processes, the user would want to know how many tasks succeeded / failed (Task Success Rate). They would also want to know the time taken by a task (Task Latency).
What we intend to communicate: Overall task progress, whether system is succeeding or erroring.
What will the viewer view this visualization for (or the action that they would take)? Alerts the user to any latency issues or task failures and they investigate by looking at additional metrics, logs etc.

The task is responsible for reading data from the read destination - metrics for read throughput (Task Bytes Read) and read latency (Message Read Latency) would help diagnose any integration issues with the read destination.
What we intend to communicate: The performance statistics of the task’s reader
What will the viewer view this visualization for (or the action that they would take)? Alert the user to performance issues when reading from read destination and they investigate by looking at read destination metrics, logs etc.
Describing each box in the diagram for what metrics are needed would become rather tedious and boring. These should give an idea on how to define the metrics needed for the service’s dashboard. Correlating with the diagram, here is a list of the metrics that are on our dashboards:
Task Success & Volume (Box A in the diagram)
Task Latency (Box A)
Task Checkpoint Success & Latency (Box H)
Task Number of Records Processed / Errored / Skipped (Box F & G)
Task Write Connector Success & Volume (Box F)
Task Write Connector Put Retry % (Box F)
Task Record Latencies & Volume (Iteration Latency - Box B to J)
Task Bytes Read & Bytes Written (Box A and Box F)
Here is an actual dashboard from the case study “Big Data: Building a Document Index From Web Crawl Archives” - the metrics are available and browsable at: https://www.letsdata.io/#casestudies

The metrics we’ve defined are mostly explanatory - there is very little exploration. However, they may lead to some curious exploration to understand the system. Our metrics infrastructure currently is not setup for exploration - specifically the speed and flexibility needed for exploration is missing. Enabling the users to filter, slice and dice the data and query metrics would be needed for exploration.
Some advice from the metrics dashboard development experience:
metrics deluge on dashboards can be distracting so try limiting to one or two metrics per component area
know what type of visualization / chart you need - our metrics are mostly time series, so we’ve used line charts. An excellent resource on choosing different types of visualization is at [3]
one doesn’t know what screen size the graph would render on, and how much data / data range would the chart have. Would a larger range or limited screen size make the chart unusable? See if a zoom can be implemented that draws the chart in a modal maximizing the screen space (this was built from experience - one of the charts were rending such that the data wasn’t legible - we implemented a zoom control)
since you are emitting the metrics, you know what they mean. You know the idiosyncrasies of your data gathering library. Document how the metric should be interpreted. We’ve built an inline help control in our chart widget that we are extremely proud of. Help is only a click away. This IMHO should be a standard in all metrics and charting controls.

LetsData Metrics Control - Inline Expandable Documentation I’ll also link advice from the charting authorities [4] [5] that should make charts and visualizations crisper. We need to implement some of these in our charts as well.

How do I Instrument?
This section is about the some technical aspects around how to emit metrics around AWS Cloudwatch - feel free to skip ahead if not interested.
We use AWS Cloudwatch Metrics throughout #LetsData. We love AWS Cloudwatch Metrics:
Simple API: the SDK is super simple to use, comes with single and batched put metric APIs [6]. At high scale, the single datapoint API can quickly get throttled (example, 10 tasks, each processing 30 messages per second, each message emitting 30 metrics ~ 9000 metrics per second!). We almost exclusively use the statistics set and they work great - no throttling issues since we moved to these!
Embedded Metrics Format: Since we’ve built our statistics set metrics infrastructure, Cloudwatch now also supports an embedded metric format [7] where you log your metrics to Cloudwatch logs and they automatically get recorded. We are yet to try this but this is the next level simplification to a very scale intensive problem. Recommend newer integrations to Cloudwatch to give this a try before the put-metric-data API.
Data Lag & Granularities: The data is available almost realtime and the per minute granularities that make it extremely useful (they also support 1-sec metrics). We emit per minute metrics and have not had any issues during investigations.
Query: Rich querying capabilities allow for data querying for large number of use-cases [8]. The API allows for multiple query results in a single call - we get our entire dashboard data in a single call. In addition, you can specify what statistics you need so the server automatically does that computation [9].
Console Metrics & Dashboards: Cloudwatch Metrics console visualizations and dashboards are great - you can construct different types of visualizations and create detailed dashboards.
Metric Streams: Metric streams are also available [10] which allow for a interesting range of new scenarios that can be built around metrics. For example, a write destination scaling / descaling service that listens to the LetData PutItem Retries metrics could automatically scale up the write destination if the retries are greater than a threshold.
What data visualizations should I create?
Our metrics are mostly time series, so we’ve used line charts. However, choosing the right data visualization for the data is critical.
[3] “Data Visualization Cheat Sheet” and [4] “20 ideas for better data visualization” do an excellent job in how to choose the right visualization and the DOs and DONTs of each visualization type. [5] “What to consider when using text in data visualizations” has excellent advice on how to annotate charts. Even if you don’t have any need for charting, you should at-least read and bookmark these three links as a great “Getting Started To Charting” links whenever you do have some charting needs. From the data visualization cheatsheet:

How do I create data visualizations?
While AWS Cloudwatch Metrics gives us the raw metric datapoints, we use Chart.js (https://www.chartjs.org/) on our website to create the data charts that we’ve shared earlier. We love Chart.js - a simple api, performant and feature rich.
We did have to write a server data translation later that converts AWS Cloudwatch Metrics datapoints to the chart.js format - essentially creating all the chart data and labels etc on the server, sending packaged data to the browser that can use it to display charts without any additional processing.
However, being such big fans of AWS Cloudwatch Metrics, we wish we didn’t have to use charts.js and the metrics data translation layer that we’ve currently written. AWS Metrics and Dashboards should natively support displaying charts and dashboards on external sites. Ideally in our multi tenant case, we would have a dashboard template that we would apply to each dataset which would generate a dataset dashboard. This dashboard can be displayed to the users on LetsData website in a frictionless manner.
Signing off
That concludes today’s presentation. Hope you’ve enjoyed reading this.
We’d like to know:
what stack are you using for metrics, data visualizations and dashboards
any additional items that should have been included when talking about data visualizations.
how we can improve
Resources:
[1] Brent Dykes’ post on differences between exploratory and explanatory data visualizations: https://www.linkedin.com/posts/brentdykes_datastorytelling-datavisualization-datavisualisation-activity-7097629835941875714-iL9b
[2] LetsResonate blog post “Growth Hack - The Case For Device Push Notifications” - https://blog.letsresonate.net/post/612587620515627008/growth-hack-the-case-for-device-push
[3] Richie Cotton - “Data Visualization Cheat Sheet” https://www.datacamp.com/cheat-sheet/data-viz-cheat-sheet
[4] Taras Bakusevych - “20 ideas for better data visualization” - https://uxdesign.cc/20-ideas-for-better-data-visualization-73f7e3c2782d
[5] Lisa Charlotte Muth - “What to consider when using text in data visualizations” - https://blog.datawrapper.de/text-in-data-visualizations/
[6] AWS Cloudwatch Metrics - “Publish custom metrics” - https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.html
[7] AWS Cloudwatch Metrics - “Specification: Embedded metric format” -https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch_Embedded_Metric_Format_Specification.html
[8] AWS Cloudwatch Metrics - “GetMetricData” - https://docs.aws.amazon.com/AmazonCloudWatch/latest/APIReference/API_GetMetricData.html
[9] AWS Cloudwatch Metrics - “Get statistics for a metric” - https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/getting-metric-statistics.html
[10] AWS Cloudwatch Metrics - “Use metric streams” - https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-Metric-Streams.html