

S3 Write Connector Improvements

Today, we are launching an S3 Aggregate File write connector - customers can now seamlessly create aggregate files on S3 from #LetsData processed records. You can read about the S3 Aggregate File write connector at #LetsData Docs.
Existing S3 Write Connector and Aggregate Files
#LetsData already supported an S3 Write Connector where each processed record is written as an individual file on S3. Here are what the files from this Write Connector look like:

While this works great, a large number of scenarios require aggregate files. It is common to have large files in S3 which have multiple records. For example, the individual files from S3 Write Connector above can be coalesced into an aggregate file as follows:

This is what we are launching today - you can now seamlessly create aggregate files with the #LetsData S3 Aggregate File Write Connector.
S3 Aggregate File Write Connector
S3 Aggregate File Write Connector is simple to get started with - define a write connector configuration and create a dataset - the processed records will automatically start getting aggregated into files on S3. Here is the write configuration schema:
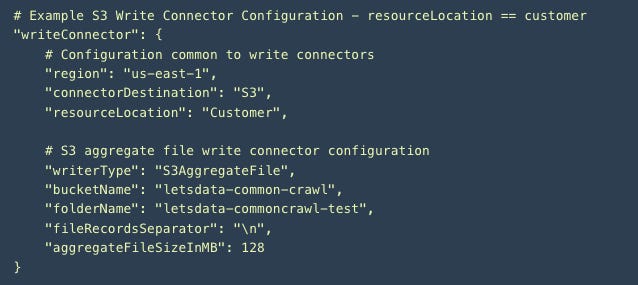
The notable configuration elements are:
fileRecordsSeparator: String - (Required) The string delimiter to separate the records in the file. For example, "\n".
aggregateFileSizeInMB: Integer - (Optional) aggregateFileSizeInMB is the write connector's output file size in MB in S3. Allowed values: [10-128]. Defaults to 128 MB.
Implementation
The implementation had a few different challenges which should make for an interesting reading.
Streaming uploads on S3
One interesting challenge was how to do streaming uploads to S3 files - here are some issues:
S3 Objects are Immutable: The S3 Objects are essentially immutable. Once you’ve created a file, it cannot be modified, only overwritten by a new file or deleted. This works great for data uploads where data files already exist, but doesn’t work quite well with streaming scenarios where data is continuously being created.
Streaming scenarios require storage that supports appends: In streaming scenarios, the content arrives with time and needs to be appended to some storage container (file, database table etc). With S3, you need to have the content to be able create an object - appends don’t work as is. (For some background in distributed file systems, maybe look at the Google File System paper)
Multipart Uploads: S3 does have a very feature rich API that allows for almost all different kinds of scenarios - in this case, the multipart uploads API seems like the recommended option - relevant snippets from the docs:
Pause and resume object uploads – You can upload object parts over time. After you initiate a multipart upload, there is no expiry; you must explicitly complete or stop the multipart upload.
Begin an upload before you know the final object size – You can upload an object as you are creating it.
In our implementation, we simply store the data on the local filesystem and initiate an upload once the file has reached the aggregation threshold. Although this seems to work well for now, we might see:
some issues from staleness in true streaming scenarios (as opposed to batch streaming). These are because we are aggregating records for a certain size before making them available in the datastore (S3)
delayed checkpoints - although we are writing to the local filesystem, we aren’t checkpointing until those records are in S3. This can cause delays in checkpoints (checkpoints happen after say 300 MB data has been processed). This can also make the solution prone to wasteful work and larger recovery scenarios. More on this follows.
Enhanced Checkpointing
In our data task, we have reader threads that read the data, compute threads that perform computations and writer threads that write to the write destination. Each of these functions is decoupled from the other - readers could have read 100 records (read pointer at 100), compute could have processed 50 records (compute pointer at 50) and writers could have processed 30 records (write pointer at 30). Here is a pictorial representation:
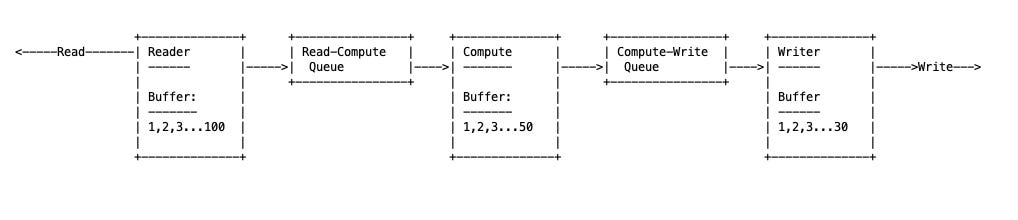
In this case, checkpoint calc is simple - when the writer flushes the 30 records in its buffer, it sends an ack back to compute and readers to trim those records from their buffers and record a checkpoint at 30.


In the S3 aggregated file writer case, there are two different flushes that need to happen before a checkpoint is created. 1.) the flushing of write records to the local filesystem 2.) flushing of the file to S3
We’d be writing records to local file and since we are aggregating, the flush to S3 thresholds are larger (for example 300 MB). If we wait for S3 flush to create the ack and checkpoints, The reader and compute buffers would be holding 300MB data each unnecessarily. (Contrived example, our implementation is quite efficient). Ideally, we can remove these 300MB records from all buffers once they have been flushed to the local file. The checkpoints can be created once the flush to S3 has completed. (So if the process crashes before the S3 flush is complete, we’ll redo the 300 MB work which is okay for now.)
This meant that our Acks and Checkpoints needed to be separated - the local filesystem writes drive the acks and the write to S3 create the checkpoints. A bit of rework and some testing later, the enhanced checkpointing is working quite well.
Conclusion
We now support writing aggregate files as well as individual files to S3 and have a variety of stateless and stateful readers to read data from S3. In addition, we are low latency and high throughput and are built around the AWS best practices for S3 - features such as backups, versioning, secure transport, audit trails, access controls etc are available by default with the #LetsData pipelines.
We’d love to know how customers might be using S3 in their data architectures and how we can evolve our S3 connectors to better serve the customers.
Thoughts / Feedback? Let us know!